Coke detector

This is our capstone project. In this project, our main goal is to experience the software development process, including project planning, project tracking, requirements elicitation, architecture design, implementation, testing, and deployment. Besides those goals, what we really do in this project is to design a system which could handle two different jobs: receipt recognition and product recognition. For the receipt recognition, our client will collect a bunch of receipt images and we need to extract useful information from those receipts, such as item names and their price. For the product recognition, our client will again collect a bunch of pictures taken in front of a shelf in a store, and we need to be able to tell that there are how many different products and what is the amount of that product in this picture. The typical input and output will be as below.


For the receipt recognition, we decide to use Google Cloud Vision solution since they have the best accuracy. For the product recognition, we decide to train our own Faster RCNN model so that we are able to extend the number of products which could be recognized.
I’m responsible for the product recognition part, so I have to train a Faster RCNN model. At the begging, we don’t know if this is doable, so we decided to prototype this idea by training a code detector model. I know that training a CNN model from scratch is very hard and time-consuming. Thus, I download the pre-trained Faster RCNN model from tensorflow. Then, I start training it by using Tensorflow. To train this model, I use AWS g3.4xlarge instance since this model is very huge and it needs a lot of memory and GPU power when training.
After setting up the environment, we need to collect the training data. We just take real pictures by using our cell phone, and then we use “labelImg” to annotate those images. We want to detect three different kinds of coke: coke-12oz, coke-zero-12oz, and coke-lite-12oz. The screenshot of labelImg is as below.
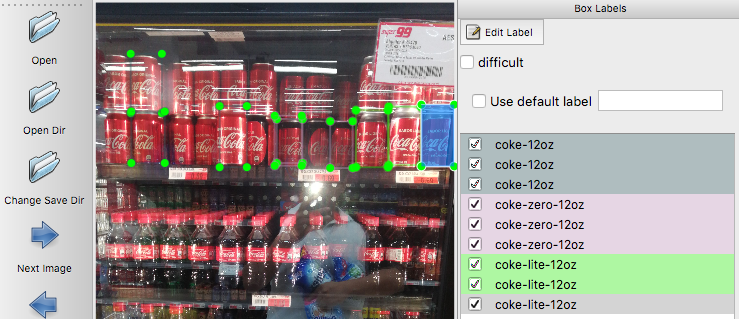
Then, after collecting these annotated images, I start transforming those annotations (bounding box) into tfrecord, which could be read by Tensorflow. I mainly base on this tutorial and customize the create_pet_tf_record.py for our need. I also modify the configuration file for the class number. Now, it’s time to train our model!
After around 2 days, I finished the training. The result was quite impressive!

Just like the above image, the left side is our annotation, and the right side is the prediction result. As you can see, the prediction can even detect more cokes than human annotation (we are lazy lol), and those detections are correct!
But there are also some bad cases like below. Many of those cans are classified as coke, and many of the cokes are not detected.

In this experiment, we only collect about 100 images. We will try to collect more images with different angles, lighting, and scale, and we will try to see if we can enhance the accuracy.